Some time ago I was working with a company that had a lot of data in multiple tables, using bigint as the primary key. At the time, it looked like a good idea to rebuild these indexes each day.
Nowadays, I am not so partial to rebuilding indexes anymore: you can gain a lot just by updating statistics instead of doing a full rebuild.
However, what I found was that when we were doing a rebuild of our tables using a bigint primary (clustered) key it would take a long time. Now, the people who came before me decided that using bigint was a good idea because there was going to be a lot of data in these tables, however, max int is 2,147,483,647. Two billion one hundred and forty seven million four hundred and eighty-three thousand six hundred and forty-seven rows.. So for most scenarios, this will be enough. Max bigint is 9,223,372,036,854,775,808. I can’t even pronounce that.
So you’ll probably pass away before you run into problems with this. And being dead will introduce other problems so you will probably not worry much about your bigints anymore then. But I digress.
Anyway, here is my case against using bigint by default as your primary key data type.
I have created a database using SSDT:
Please copy this from my GitHub if you’re interested.
Anyway, what this will do is that it will insert 5 million rows (which is peanuts) into my database.
After running an index rebuild script this was the outcome:
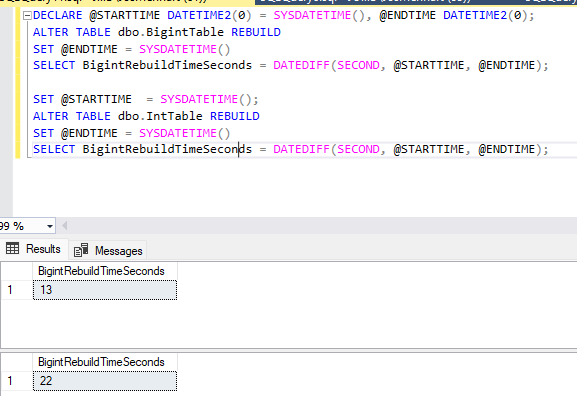
So, with the same amount of rows, and similar data, the bigint table took almost twice amount of time to rebuild its indexes. I have retried this multiple times and each time was different, however, rebuilding a table with a bigint clustered key always took more time to rebuild than an int table. Which makes sense of course.. But I wouldn’t have thought the difference to be so large.
Of course, the code I used for testing is available on my GitHub.